I’m having a hard time with some of the public narrative that AI spells out the demise of the developer as a profession. LLM-assisted development is a generational shift in how techincal work gets done–and those best positioned to benefit from it are the ones who understand the code being produced and the infrastructure on which it runs. The shift may lead to an increased demand for people with technical expertise and the creation of VibeOps as a category.
Vibecoding and a new wave of software development
First, I would be remiss to not mention that I think ‘vibecoding’ is such a perfect description of using AI to build and debug. Vibes really capture the experience of what it’s like to use an LLM for building software–trying to coax a realistic solution out of a tool that is, architecturally, an engine of probabilities. These tools lower the barrier to entry for going from a blank canvas to a prototype and they make running experiments more feasible for someone with either no or shallow technical proficiency.
We have seen this pattern emerge before, when visual programming and later no-code were the buzzy paradigms that would change the way technical work was done. And just as with no-code, my skepticism that this leads to an apocalypse for the profession runs high. It’s not that these tools are bad or wrong or anything of that nature. I think of them more as enabling the creation of a tsunami of prototypes, experiments, and new applications; I can spend less time trying to recall and read the docs on flex-box and more time focused on the actual creation and extraction of value while building software.
All along the historical continuum from visual programming to no-code to vibecoding, the same premise holds true: the tools don’t approximate a developer, they just shift the focal point of a developer’s work to a different layer. Vibecoding gives nontechnical creators an on-ramp to learning technical skills, lowering the barrier of entry to building a product.
But the fractal complexity of software and infrastructure remains a problem that doesn’t vanish in the face of AI. No matter how many new integrations or layers of abstractions build up around LLM-first workflows for software development, issues resulting from internet scale, security vulnerabilities, or inefficiencies introduced in a pull request will necessitate technical expertise. Users with limited technical expertise are often surprised at the level of complexity that lurks beneath the surface of a front-end. In reality, only a portion of a developer’s job is actually writing code.
Negative expertise
Marvin Minsky's 1994 essay on Negative Expertise
is always on standby in the back of my head when thinking about AI, quickly rising to the fore when contemplating AI in the context of software development. The gist of it is that when we think of intelligence and expertise, we often equate it to “knowing what to do.” As Minksy puts it, that’s only half of the picture:
We tend to think of knowledge in positive terms – and of experts as people who know what to do. But a ’negative’ way to seem competent is, simply, never to make mistakes. How much of what we learn to do – and learn to think – is of this other variety? It is hard to tell, experimentally, because knowledge about what not to do never appears in behavior.
Quite obviously, we can see issues playing out because LLMs are trained on mostly public behavior and rewarded when they mimic and synthesize these behaviors. Unfortunately, when nontechnical users delegate too much responsibility to these systems, the resuts can be quite painful:
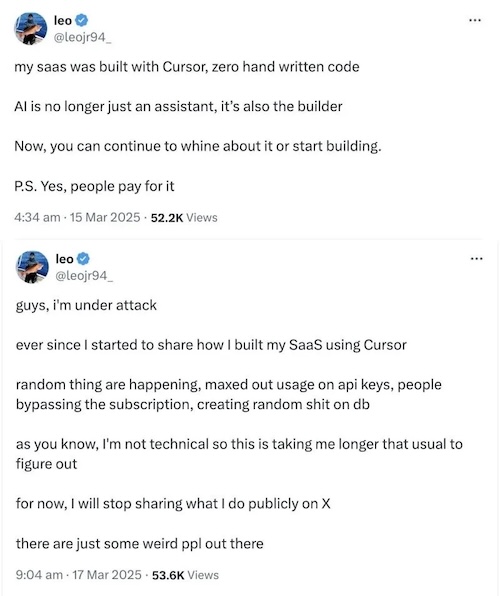
Building a web app is only partially about code. Yes, you need functional code. Then you also need to figure out things like secrets, config, auth, orchestration, and more, each with an endless list of best practices and edge cases. I believe that for the forseeable future, those things will continue to be the purview of a human developer.
What it means for engineering as a discipline
Whether AI is generating all of the code or it’s reviewing and assisting a professional developer, getting to a prototype has never been easier or cheaper. That’s a wonderful thing for all of us building an MVP, but it doesn’t address the systems thinking that should be involved in making high quality software, nor does it necessarily address security best practices or efficiency in production code. With a large enough context window and more training, that will likely improve, but I don’t think it removes the need of a developer that knows both what to do and what not to do.
There’s a reason we call computer science an engineering discipline. It’s about systems thinking and provable correctness. If I’m going to drive over a bridge, I don’t want it to just approximate structural soundness on the surface, I want it to actually be structurally sound. Software really isn’t so different.
The rise of AI commoditizes some skills while increasing the value (and a demand premium) for other skills. The value-per-unit of expertise shifts–knowing how to align something correctly in a div decreases in value but knowing how to design and orchestrate data and usage at scale safely increases in value. Fundamental understanding of the code being produced is and will be inherently valuable. Even if you think that AI is truly going to take over everything, who builds, deploys, and monitors AI? Developers.
A call for VibeOps
Codebases have always had an evolution path; now, those internal cycles will iterate more quickly, and developers are responsible for guiding the evolution in safe ways. When there’s a technological paradigm shift in software development, there is always a need for a new genre of tools and abstractions to take advantage of the shift. As public cloud primitives began to take over infrastructure, DevOps emerged as a category to bridge the divide between developers and tasks that would have historically been part of IT, which was responsible for racking servers. It feels like the next wave of that will be VibeOps: tools that bridge the divide between LLM-assisted coding and responsible development practices. I’m not sure what this ends up looking like, but some of the things that are circulating in my thoughts are:
- Intelligent safety rails – think of tools that sit between AI-generated code and the production environment, acting as sophisticated guardrails. These could use static analysis and instruction sets specifically tuned to catch some of the more common antipatterns, thereby making some of that negative expertise explicitly codified, and could help prevent injection vulnerabilities or ensure proper auth in session management
- Context-aware infrastructure orchestration – AI may be great at generating application logic and yet struggle with operational concerns at the infrastructure layer. VibeOps tools could generate appropriate Docker/k8s configs and help instrument CI/CD pipelines with health checks, resource limits, and scaling policies
- Tools to help prune and shape codebases – in my experience, LLMs have a strong bias toward adding code but rarely remove code. I can’t imagine this is a long-term sustainable status quo
- Continued work in dependency management and software supply chain – finding safe packages and approved registries and enforcing compliance (see slopsquatting
)
- Edge case management – LLMs tend toward writing code along the path of least resistance, so tools that use formal verification techniques and/or property-based testing could help manage some conditions that weren’t anticipated by the LLM
- Performance and resource benchmarking – tools that help align the infrastructure config and address things like networking, security, and performance
The unifying theme across these VibeOps tools is that they serve as a bridge between the creative, generative power of AI and the rigorous, safety-conscious practices that define professional software development, which must include negative expertise. They don’t replace human expertise–they amplify it by handling the routine but critical work of making AI-generated code production-ready.
Regardless of whether we call it VibeOps, we need a category of tooling that helps makes sense of the ocean of imprecise-but-somewhat-functional code that is making its way into pull requests. And I believe that those tools will be designed and used by engineers. If you’re a founder building something in VibeOps, let’s chat!





